
Ensuring the Security of Large Language Models
Introduction
In the ever-evolving landscape of artificial intelligence, Large Language Models (LLMs) have emerged as transformative tools, reshaping how we interact with technology and harnessing the power of natural language processing. The current renaissance we see with AI offers us unparalleled opportunities to transform our organizations regardless of industry.
At least, that’s what we all hope. The reality is that while that all may be true, it also presents some novel threats that typically haven’t been fully considered. The seemingly endless ongoing security challenges our organizations face can lead to devastating consequences if there’s a lapse. Now, introduce a tool that can generate human-like text, communicate with customers, and make critical business decisions, all at the speed of light. Despite their risks, AI is a part of our businesses now, and safeguarding them from potential vulnerabilities and threats becomes a paramount concern. If you have yet to deal with these systems, don’t worry; it’s just a matter of time.
How do we integrate this technology into our business securely?
Understanding the LLM Renaissance
Before delving into the intricacies of LLM security, it’s imperative to grasp the significance of LLMs’ recent rise in popularity and why this differs from previous incarnations of similar AI efforts. While this technology is not new, it has recently grown in leaps and bounds and is more readily available now than ever. A Large Language Model (LLM) is a form of generative AI that can comprehend natural language text and generate various outputs from text, images, sound, and even video. These models can perform numerous tasks involving human language and have significantly advanced the field of natural language processing (NLP).
The culmination of extensive datasets and complex neural networks allows these machine learning models to understand, generate, and manipulate text. They can also handle other forms of media like images, sound, and video, doing so in a way that closely mimics human cognition.
LLMs are becoming integral to countless applications across industries, from virtual assistants to automated content creation. However, we must also confront their operation’s ethical and security implications to ensure that LLMs produce reliable, unbiased, and secure outputs.
The scale of data these models use for training is one part of this that makes this recent rise in AI and LLMs different from past attempts. The term “Large” in “Large Language Model” is just that. The power of these models relies on the massive amounts of data used in their training. For example, in the case of ChatGPT, this could be everything readable online. For LLMs with a specific purpose, this training data could be much smaller but more focused on their particular task. The cost of training these models until recently has also been prohibitive, consisting of billions of data points; the costs can reach into the millions to produce a well-trained model (source).
The Importance of LLM Security
As the usage of LLMs expands and these models become more integrated into various applications and platforms, it’s crucial to address the challenges LLMs pose to ensure the trustworthiness and safety of LLM-driven systems. While we may be familiar with challenges around misinformation (or disinformation) and popular implementations prone to generating false or misleading information (or hallucinations), other challenges may need clarification when integrating LLMs into an organization. Here are just a couple of these other potential security challenges:
Privacy Concerns
LLMs may inadvertently reveal sensitive or personal information. For example, they can generate text that unintentionally exposes confidential data or breaches privacy regulations, leading to privacy violations and legal consequences.
Bias and Discrimination
LLMs can inherit biases in their training data, potentially perpetuating societal biases or producing unfair or discriminatory content. Addressing bias and ensuring fairness in LLM outputs is a significant challenge.
Adversarial Attacks
Despite their advanced technology, LLMs are susceptible to adversarial attacks, just like traditional technologies. Attackers could intentionally input data to trick or manipulate the model. Such attacks can lead to incorrect or malicious responses. Depending on the nature of the LLM and its access, a new kind of threat known as the “Confused Deputy” attack, where a malicious user, through prompt injection, could cause the LLM to perform unintended actions on their behalf. Depending on the nature of the LLM and its access, a new kind of threat known as the “Confused Deputy” attack could be used, wherein a malicious user causes the LLM to perform unintended actions on their behalf through prompt injection.
Legal and Ethical Risks
LLM-generated content can raise legal and ethical questions or violate copyright or intellectual property rights. ChatGPT has come under much scrutiny on this issue due to OpenAI–the team behind ChatGPT–not getting consent to use a host of data for training, an issue that is currently making its way through the courts (https://www.bbc.com/news/technology-66866577). Vetting training data and ensuring it’s from ethical and legally acceptable sources is imperative to avoid potential lawsuits. It’s unknown how these existing lawsuits will play out long-term, but the results could have far-reaching consequences for these readily accessible models, potentially impacting early adopters of this new technology.
Security of LLM Models
The infrastructure and systems hosting LLMs must be secure. Unauthorized access to LLM models or their servers can result in data breaches or manipulation of the model’s behavior. This is true whether the LLM is meant for internal use only or for external uses. Ensuring the security of the LLM involves all the traditional approaches to security as well as that of DevSecOps and MLSecOps.
Other Malicious Use Cases
Malicious users can use LLMs to generate content that promotes hate speech, incites violence, or spreads extremist ideologies. Not great for the business’s brand. The LLM landscape is currently evolving rapidly, and as organizations adopt this technology, the full extent of how malicious actors can use this technology will no doubt also include novel attacks we haven’t seen yet. This past year at DefCon, thousands of hackers took part in efforts to hack popular AI programs to uncover additional threats and vulnerabilities and cause the AIs to go rogue (https://www.npr.org/2023/08/15/1193773829/what-happens-when-thousands-of-hackers-try-to-break-ai-chatbots).
Addressing these security challenges requires a concerted effort from developers, researchers, policymakers, and the wider community. On Monday (10/30/2023), the Biden-Harris administration issued a new Executive Order to manage the risks of AI by setting new standards for AI safety and security. But the policymakers in Washington aren’t the only ones that have been busy; the OWASP (Open Web Application Security Project) community has extended its focus to LLMs by creating the OWASP Top 10 LLM Project (https://www.llmtop10.com/). This project seeks to identify and mitigate LLMs’ most critical security risks, offering guidance and best practices to developers, organizations, and researchers. Ongoing research and collaboration are essential to securing the deployment of LLMs. We won’t go through each of the ten vulnerabilities here, as the Top 10 LLM Project does a fantastic job of that and should be required reading for anyone working on an LLM project. Instead, let’s discuss why existing approaches to a third-party security pentest aren’t enough.
Why existing approaches aren’t enough.
It’s clear from discussions with clients who are at different stages in their journey of integrating AI into their business processes that they know this technology is different but are still determining the right approach to addressing their security concerns. Why is it that this particular technology is so unique? Aren’t we just integrating with another API or third-party component? In most cases, a dynamic application pentest is sufficient to find the most critical issues and even more so when combined with a rigorous secure code review. Before addressing the right approach to LLM security, we should understand why this approach is insufficient and only one of the solutions to address AI’s unique challenges. We must go further.
Consider the scenario where the business integrates with a third-party AI tool to aid in customer service endeavors. Think of your typical website chatbot: the chatbot is integrated into the organization’s primary website and is coming up for its annual application pentest. Let’s also assume that the chatbot and its third-party APIs are in scope and that the pentester is familiar with testing LLMs from a malicious perspective. From this perspective, the pentester could test the chatbot for common vulnerabilities such as Cross-Site Scripting (XSS) or SQL Injection (SQLi). The tester could also see if the chatbot is susceptible to prompt injection. Can the chatbot be tricked into disclosing information that it shouldn’t? What information does this chatbot have access to, based on its training, that it could reveal about your organization? Depending on the actual nature of the integration, it may not be a lot. However, let’s keep digging and ask a few other questions. An LLM is only as good as its training, which is only as good as its training data. What data is this model trained on? How do the developers ensure the training doesn’t introduce biases into the model? What if the training data itself is biased? These are important questions and ones that a pentester approaching this from a traditional application pentest can’t answer.
Let’s take this example further. The business concludes that this third-party integration isn’t working well and decides that bringing it in-house would be a better approach. Developing a custom model trained on the company’s data could better help our heroic customer service people serve customers better. What data exactly is going to be used to train this model? Where is this data being stored? Who has access to it? Remember those supply chain security issues? They apply here, too, if using pre-trained models or training data from third parties.
An issue that we are actively seeing during our application pentests right now is when an organization decides to take the “query your data” approach with LLMs. A document-heavy organization uses this LLM to parse documents so that users can ask natural language questions regarding them. There’s no custom training in this case; the chatbot has access to troves of raw data in these documents. A malicious user could cause the LLM to disclose much of this information. There are also the downstream impacts of giving an LLM excessive agency and what to do about the chat history and the raw data.
These are decisions that a regular application pentest can’t bring to light. We can include a secure code review there, but that also has limitations. Approaching it from a different angle, we could start with an architecture assessment, but that will only tell part of the story.
So, what is the right approach?
How do we address LLM risks?
It only takes a quick look at The OWASP Top 10 LLM Project to see that it covers several vulnerability categories. We see some familiar things here, such as input handling and data validation, information disclosure, and denial of service. We might need to be made aware of a few, such as a malicious hacker intentionally poisoning your training data. The diagram in the OWASP Top 10 LLM (see below) highlights this point even further by placing these vulnerabilities in the LLM application data flow.
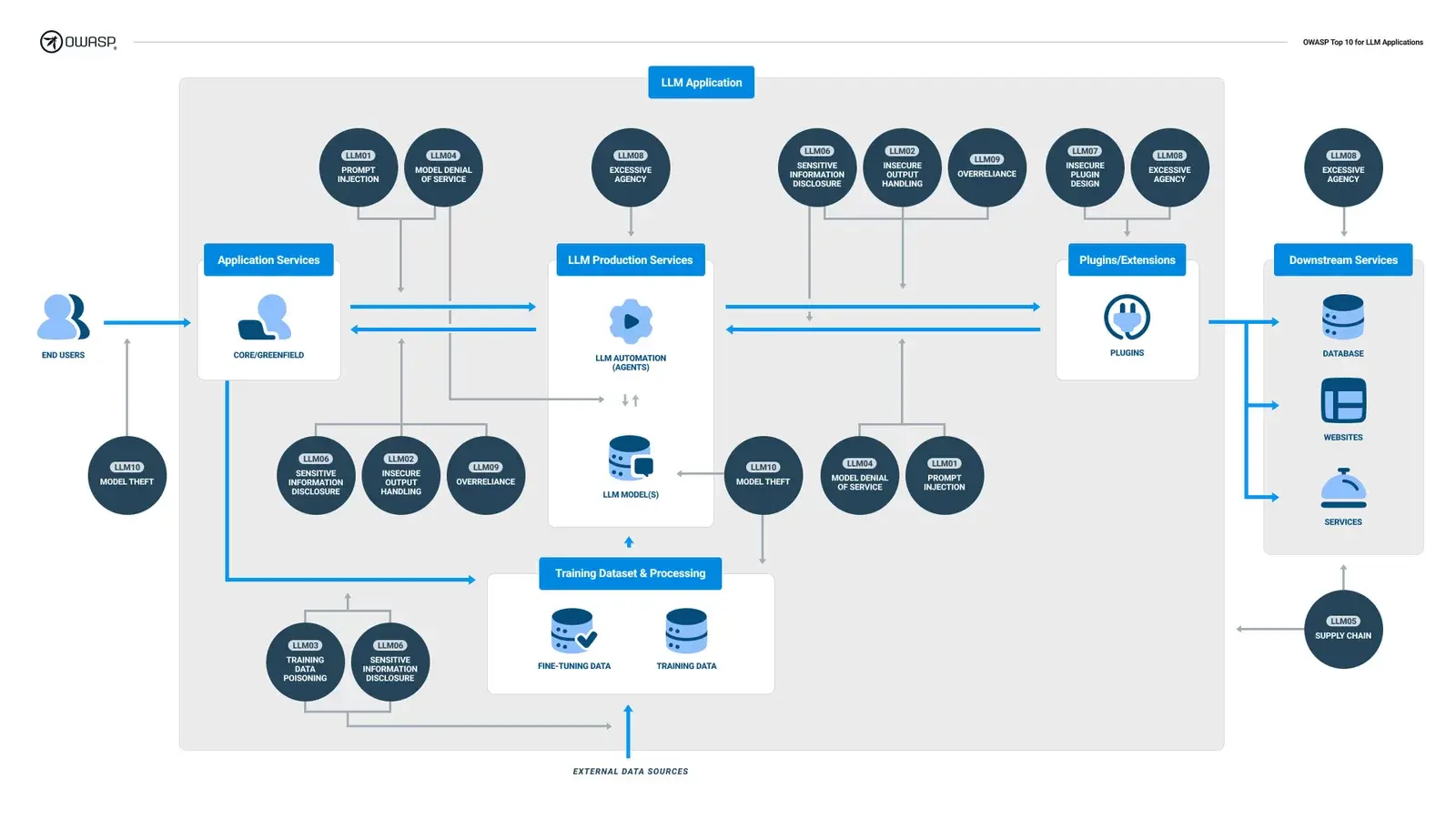
Doing an external black box application pentest is not enough to ensure your AI project is on solid footing. An approach must include dynamic testing but also needs to go deeper to include a review of the architecture and training methodologies and to have people that are skilled in all these areas. They know their way around not only application pen-testing but DevSecOps and MLSecOps.
Not a small feat at all. And one that not many can do alone. It would be best if you had a team. That’s why we approach AI/LLM assessments with a hybrid approach—involving a cross-cutting team among our tactical and strategic application security teams. We assess all aspects of the LLM application. We test its runtime aspects via dynamic testing and perform an architecture review to identify integration and access control issues. We perform a supply chain review to identify the problems with training data or the training process.
Conclusion
LLMs have become popular due to their AI breakthroughs, ability to perform various language-related tasks, versatility, and innovation potential. Their popularity is likely to continue, bringing twists in existing security measures and new risks we may need to be more familiar with. Addressing these risks requires a multi-disciplinary team that can look at the system holistically from every point of view. A team that is familiar with the existing AI landscape and where it’s headed.