
WWDMD – What Would Dade Murphy Do? – Reconnaissance & Intelligence Collection for External Penetration Tests
Author: Matthew McCorkle
Supporting Author: Heather Fetty
Special Thanks: George Raileanu, Katelin Shaffer, Rose Pineau
Introduction
This article is written for the penetration testing community and assumes the reader understands the basic concepts of penetration testing. It will benefit anyone looking to identify information and assets within an external scope that otherwise might not be easily discoverable. It is written from my perspective as a consultant providing external penetration testing services for a client. Therefore, this post won’t be like the typical blog post with regurgitated information. The information I present is personally relevant to techniques I use during real-world penetration tests for clients.
If you are not a penetration tester and want to understand the risks associated with an external attack surface, this is still a valuable blog post. Readers should have some knowledge of Linux environments in regard to command-line use.
Penetration testing is all about enumeration. Solid enumeration leads to a thorough understanding of the client’s environment. I will discuss in-depth enumeration strategies I implement during external penetration tests, which can lead to discovering as much actionable information as possible about your client’s external attack surface. I have included a mindmap that outlines all of the techniques I have described in this blog series. You can find it on my personal GitHub here. I want to give thanks to Orange Cyberdefense as I used their AD mindmap as a reference for my mindmap.
By the end of this post, I want you to look at the information provided in this blog like Ramόn Sánchez (The Phreak, a.k.a The Phantom Phreak, a.k.a. the King of Nynex) looks at Dade Murphy when Dade is changing his class and grade in the school’s student database.

Enumeration
Enumeration is the process of listing or counting something. To conduct external penetration testing, I need to gather as much information about the client’s scope as possible. I achieve this through open-source intelligence collection and reconnaissance. While technically a form of reconnaissance, I’ve mentioned open-source intelligence separately to underscore its significance, not to suggest it’s distinct from reconnaissance.
Merely gathering data isn’t sufficient if I cannot analyze and interpret it effectively. Therefore, I will demonstrate how to utilize data from one technique to improve/enhance the results of another.
Why is good reconnaissance valuable to a client?
Thorough reconnaissance enables a consultant to uncover information that a client may not be aware of. This insight can help clients perform appropriate risk analysis on newly identified information and mitigate or act on the information appropriately.
GitHub is a great place for finding sensitive information. On a previous external penetration test I discovered a software developers’ personal profile that contained sensitive customer information such as name, address, email address, purchases. The information was uploaded in the repository two years prior to when I discovered it. It is unknown how many times that information had been accessed by the time I discovered it. Within 24 hours the client had the information removed and was working with archive companies to remove snapshots of the data.
As a penetration tester, my goal is to add value to a client’s perspective regarding their in-scope attack surface. Clients trust my insight and abilities to identify sensitive information and misconfigurations within their environment. By providing clients with a comprehensive analysis of their external attack surface, they can analyze risk and apply mitigation strategies that align with their needs.
Methodology
Enumeration, in its simplest form, should be systematic and repeatable. However, it should be noted that, due to constantly changing environments, repeatable does not mean you will achieve the same results every time. Perhaps a subdomain is taken offline, or a data point is requested for removal by the client after testing. Therefore, repeatable only refers to the process steps and not the actual data acquired.
I have included only one paid resource that I use regularly: Shodan.io. The developers of Shodan often offer lifetime membership opportunities for $5.00 USD throughout the year. I highly suggest you obtain a lifetime membership when you can. All other resources that require API keys offer free options for the user. However, some API keys have restrictions on their use.
Typical Process
A simple visual process of how I perform enumeration is:
Find Data → Refine and Clean Data → Validate Data → Act on Data
“Intelligence is the product resulting from the collection, evaluation, collation, interpretation, and analysis of all available data and information”
https://www.uscybersecurity.net/csmag/the-differences-between-data-information-and-intelligence/
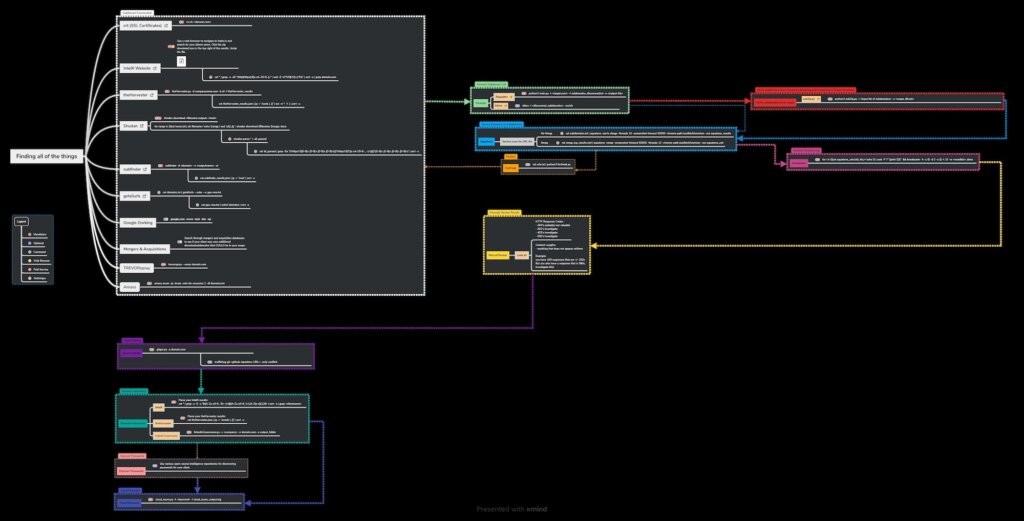
Throughout a penetration test, I am constantly applying the data, information, knowledge and wisdom model from the US Cyber Security Magazine below. As you read through this article, stop and think about what part of the model our enumeration efforts are being applied from. For example, subdomain enumeration is a data collection method. Analyzing which subdomains are in-scope and out-of-scope gives meaning to the data, which turns it into information. Once I perform directory brute-forcing attacks on the in-scope subdomains, I gain knowledge of potentially sensitive information. As I analyze the knowledge, I can determine how to apply action towards those brute-forced endpoints, which will give us the wisdom needed to move forward with exploitation and other attack opportunities.
{kind=link}
A website and book I like to reference while performing open-source intelligence collection activities is Open Source Intelligence Techniques by Michael Bazzel and his accompanying website, IntelTechniques. Michael Bazzell has become one of the most prominent names in the OSINT community. He has laid out all the tools he references in his book on his website.
Throughout this blog, you will read about various techniques and tools. I have annotated which strategies I implement every time, regardless of the customer, and which strategies I use as necessary.
The techniques that I use for every external penetration test will be marked with a bold M. Strategies I implement as needed will be marked with a bold O.
Each technique that leverages a tool will follow the below format:
website M (type of information): Description of how and why I use it.
-i Input file containing hostnames separated by line
-o Output file where you want results written to
# IamaSuperCoolTechnique.py -i <hosts> -o <output_filename>Subdomain Enumeration
I consider subdomain enumeration as the foundation for discovery during an external penetration test.
No matter the size of the company or the amount of time I have for a project, I always perform all the techniques I have identified with an M in the order I list them. I specify the order because some techniques take a lot of time and should be started as soon as possible.
An overview of the subdomain enumeration process I implement is below: Passive Reconnaissance → Active Reconnaissance → Permute List → Resolve full list → Sort for in-scope/out-of-scope subdomains → Profit$
Passive Reconnaissance
Discover all the subdomains using passive tools such as CRT.sh, Shodan, IntelX, etc.
crt.sh – M – (certificate information): This site aggregates SSL certificate information from the internet. Certificates often contain subject alternative names that are subdomains for an organization. Depending on the organization, it can take a very long time to grab all the certificate data. Therefore, I start this first before anything else. I use crt.sh (tool), a shell script to automate the collection and parsing of domains from the certificates.
Below is an example command for using crt.sh (tool).
<KEYWORD> can be the name of the organization, or the domain of the organization. Try not to use spaces.
crt.sh <KEYWORD>Intel X – M – (breach data): Intel X provides an easy-to-use search feature with API support. You can use Intel X’s website to search for information, or you can interact with the data directly using an API key. I often implement my Intel X API search using theHarvester, which is discussed next. However, if you have access to a commercial account, you can use the Intel X website to search for keyword(s) and download all the data as a zip file. Once I have extracted the zip file, I then use a Linux device to search through the data using grep, awk, sed, tr, and cut to manipulate the data to extract subdomains. Below is a screenshot of the location of the zip file download button and an example one-line command for extracting subdomains for an Intel X file dump.
NOTE: You will want to review the subdomains discovered and ENSURE that your list contains only subdomains in the format sub1.domain.com.
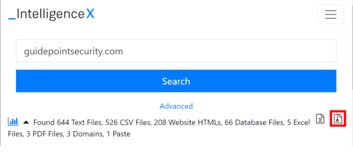
Extract subdomains for an unzipped Intel X search file. This command uses grep to search through each file in a directory for any URLs that start with http:// or https://. Then, it extracts the subdomains and domains, removing http:// and https:// from the output. Finally, the command sorts it and ensures duplicate values are not found, and then the command uses grep to only show you results with the subdomains you need.
# cat * | grep -a -oE "(http|https)://[a-zA-Z0-9.-]+" | sed -E 's/.*:\/\/([^\/]+).*/\1/' | sort -u | grep domain.comtheHarvester – M – (multiple passive search sources) – theHarvester queries many publicly accessible and some paid services to aggregate data into a single tool output. theHarvester works best when provided with as many API keys as you can access.
Below is the command I use when interacting with theHarvester.
-b specifies the sources to use; in this command I select all sources. theHarvester will skip API-required sources that do not have an API key in the configuration file. To find out more about configuring theHarvester, visit the API keys section of the documentation.
-f writes the output of theHarvester to a filename of your choice.
# theHarvester.py -d companyname.com -b all -f theHarvester_resultsBelowis a Linux one-line command for extracting subdomains from the results.
# cat theHarvester_results.json | jq -r '.hosts | .[]' | cut -d ':' -f 1 | sort -uShodan – O – (proprietary database)- This is a paid-for service. Often, you can find a sale from Shodan where you can purchase a lifetime membership for $5 USD. Shodan allows API access with its database. You can interact with Shodan in two different ways: either with the Shodan CLI tool, or via other tools that take advantage of Shodan CLI libraries. I like to interact with Shodan using the Shodan CLI tool.
Below is the command I use to interact with Shodan using Shodan CLI to download a Shodan json.gz file on a host.
# shodan download <filename output> <host>Here is a one-line for-loop command that iterates through a list of hosts to download the file for each host.
# for range in $(cat hosts.txt); do filename=`echo $range | sed 's/\//_/g'`; shodan download $filename $range; doneOnce I have my Shodan json.gz files, I use Shodan CLI to parse the files into one combined file.
# shodan parse * > all_parsedThen, I use grep and some regular expressions to extract a list that is just hostnames and IP addresses.
# cat all_parsed | grep -Eo '(?:https?://[0-9]+.[0-9]+.[0-9]+.[0-9]+)|(?:https?://(?:[a-zA-Z0-9.-_~]+))|(?:[0-9]+.[0-9]+.[0-9]+.[0-9]+)' | sort -uAs with all commands on the internet, you should verify these and ensure that your data is being parsed correctly.
subfinder – M – (multiple passive sources) This tool uses passive methods to collect subdomains from many sources. Some sources require API keys; refer to that documentation here. I use the following command to query the sources for subdomains and output the data as a JSON file.
-oJ enables JSON output.
# subfinder -d <domain> -o <outputname> -oJI use the following command to parse the JSON file and extract subdomains.
# cat subfinder_results.json | jq -r '.host' | sort -ugetallurls – O – (multiple passive sources) – Wayback Machine contains a plethora of archived web data. I take advantage of the archive by using getallurls, which queries the archive and other sources for subdomains. Below is the command I use to extract subdomains from the archives.
--subs enables the subdomain module.
# cat domains.txt | getallurls --subs --o gau-raw.txtI use unfurl to extract subdomains from the results.
# cat gau-raw.txt | unfurl domains | sort -uGoogle Dorking – O – (it’s Google) At this point, you should be at the end of your passive subdomain enumeration phase. What I like to do, if I have time, is to extract each subdomain discovered from my main passive_subdomains.txt file. In other words, if I had www.google.com then I would extract just www.
Next, I like to put these into a text editor and create a massive google dork search. This can get ugly, but ultimately, my search looks like something like the example below.
Using the search operator symbol, the dash (-), instructs Google to remove results with the subdomain specified. Then, I review the results (if any exist) and determine what subdomains I might have missed with other passive efforts.
# google.com -www -test -dev -qaMergers & Acquisitions – O – I had a client that started as a massive organization 40 years ago. Over time, the organization was sold into various subsidiaries. The client owned many of the subsidiaries. During my research, I determined multiple organizations with various domains and subdomains that were technically still owned by the client, but which the client was unaware of. By identifying these merged and acquired businesses, I was able to provide additional insight to the client regarding their external attack surface.
At the time of writing this post, I have not identified a technique for discovering this information using automated methods without paying for expensive API access. However, you can reference various open-source websites that host data that could lead to additional insight into your client. Below is a list of websites that can help:
https://inteltechniques.com/tools/Business.html
https://guides.loc.gov/mergers-acquisitions-joint-ventures/current-transaction-data
Active Reconnaissance
TREVORspray – M – (Microsoft tenant information) – TREVORspray has the recon module, which is technically active reconnaissance, but it queries from Microsoft cloud provider services. Therefore, classify this in a manner that is applicable to your rules of engagement. TREVORspray lists out Microsoft tenant information which can include subdomains associated with a tenant that you may not have been aware of.
# trevorspray --recon domain.comAmass – M – I use Amass to perform an initial round of brute-forcing domains to discover subdomains. Below is the command I use.
-ip Outputs the IP next to the subdomain discovered.
-brute Bruteforce option.
-min-for-recursive Minimum level of subdomain to perform recursive brute-forcing.
-df File with domains separated by line.
# amass enum -ip -brute -min-for-recursive 2 -df domains.txtFavFreak – O – DISCLAIMER: I have not used this technique, but I am aware of it and wanted to share it as it seems like it can be useful. If you can find a favicon for domains/subdomains, then you can query the hash for that favicon file. This Python tool automates the discovery of other subdomains with the same favicon hash. Please review the tool for use in your environment.
Permute List
Permutation, in this context, is the process of taking a list of identified subdomains and extracting keywords and phrases from them to create a list of potential subdomains. I will use Regulator to perform a smart regex method of permutation. If the scope is large, then I move to the next step, which is resolving the list of subdomains and comparing that to my scope.
If the project scope is small, then I take the subdomains and use Alterx and the -enrich option to create a second generated list of possible subdomains. I combine both my Regulator and Alterx permuted lists while ensuring only uniquely generated subdomains are present. At this point, I move to the next step, which is resolving the list of subdomains and comparing that to my scope.
Regulator – M – This tool uses regex and a ranking system to create permuted lists of potential subdomains from a list of discovered subdomains. Here is a great article discussing the function of Regulator from the developer.
# python3 main.py -t <target.com> -f subdomains_discovered.txt -o <output-file>Alterx – O – This is another permutation tool that can also create permuted lists of subdomains from a list of discovered subdomains. Here is a great article from ProjectDiscovery discussing Alterx.
# alterx -l <discovered_subdomains> -enrichVerify the Subdomains are in Scope
Next, you should resolve the subdomains and separate them into in-scope and out-of-scope subdomain lists. Then, attempt to resolve each subdomain to create a list of live hosts. I have included a Python script sub2ip.py that does this and then outputs the subdomain and IP address to either an in-scope spreadsheet or an out-of-scope spreadsheet.
Profit$
To provide valuable intelligence with actionable insight, I need to have relevant and clean data. By the end of my subdomain enumeration phase, I have identified all subdomains within the time limits of testing. If I gathered subpar data, then my permutations would be subpar, and my overall potential in discovering sensitive information in a client’s environment would be reduced. By putting extra effort into intelligence gathering, I have set myself up for success in finding actionable and relevant information for my client.
Service Discovery on Subdomains
In-scope subdomains should get a service discovery of some sort. That could include network scans, domain flyover, etc. Regardless of the service discovery option(s) you choose, you should have a list of subdomains and live services (ports) discovered on each subdomain. I like to perform a domain flyover on all the scope provided by the client as well as every subdomain discovered. Sometimes, you may be duplicating your efforts with this method; therefore, I like to do the domain flyover separately for scope and subdomains. I use Aquatone to perform domain flyovers for two reasons. Aquatone provides an HTML file that allows a user to visually inspect screenshots, hosts, and detected technologies. Additionally, the most valuable output of Aquatone is the URL file created by the tool. However, Aquatone has its limitations and can only handle 200-300 hosts before it crashes. Therefore, if you have a large scope, consider using GoWitness, eyewitness, Nuclei, and other tools that offer domain flyover automation.
Aquatone – M – A directory flyover tool that accepts standard input, or Nmap XML files to take screenshots of web services.
Without Nmap:
-ports This option enables Aquatone to attempt to connect to each subdomain using each port described in the xlarge option on Aquatone’s documentation.
# cat subdomains.txt | aquatone -ports xlarge -threads 10 -screenshot-timeout 50000 -chrome-path /usr/bin/chromium -out aquatone_resultsWith Nmap:
-nmap This option enables Aquatone to scan an Nmap file and attempt screenshots against each web port Nmap identified.
# cat nmap_tcp_results.xml | aquatone -nmap -screenshot-timeout 50000 -threads 10 -chrome-path /usr/bin/chromium -out aquatone_urlsThe URL file output by Aquatone can be used to perform directory brute-forcing attacks against the endpoints.
Directory Brute-forcing (directory busting)
Directory brute-forcing is ultimately where I find endpoints, forgotten files, upload mechanisms, and authentication mechanisms that contain security misconfigurations or sensitive data that our clients are unaware of. This is why I place such a large amount of effort into effective subdomain enumeration. Hopefully, if there is something hidden, you can find it.

With the URLs extracted from the domain flyover tool, I like to move into directory brute-forcing. Of course, this can take a very long time, depending on the wordlist you use, so plan appropriately. I like to use a combination of the raft-small lists from SecLists and will often add the IIS combined list iisfinal.txt from Carlos Polop over at HackTricks. You could also add specific wordlists for technology that you know exists within the client environment, such as an Adobe ColdFusion wordlist from SecLists and others.
It is important to tune your directory brute-forcing scans so that you are only seeing and reviewing information that COULD be relevant to you. Perhaps certain status codes are not interesting for the testing you are doing, or perhaps certain file extensions are not necessary. A good directory brute-forcing tool allows you to tune the scan at a granular level while the scan is happening. I use feroxbuster for the control it offers while brute-forcing, such as thread control, filter manipulation, and other scan manipulation options while the tool is running.
The following for loop concatenates a list of discovered URLs and runs Feroxbuster against each URL. You should adjust your Feroxbuster command to use the filters and options that work for your needs.
feroxbuster – M – Directory bruteforce all your in-scope endpoints!
-k Disables SSL certificate verification on the host.
-u The URL to test.
-d Depth of recursion to perform directory busting attempts.
-o Output file for scan results.
-t Thread tuning the speed of the scan.
-w Wordlist to use for directory bruteforcing.
# for i in $(cat aquatone_urls.txt); do j=`echo $i | awk -F '/' '{print $3}'` && feroxbuster -k -u $i -d 3 -o $j -t 10 -w <wordlist>; doneManually review directory brute-forcing results
Finding endpoints that shouldn’t be exposed is critical for our client’s awareness and can lead to additional security issues that the client likely has not realized.
Reviewing the directory busting results should be completed manually with meticulous detail. I like to look at my Feroxbuster files, scanning for content length differences and HTTP response code changes. Usually, pages that do not appear like the rest (different content length and HTTP response codes) contain possibly valuable information. I use a text editor that allows easy navigation between files in a folder from within the application. Sublime Text, VS Code, and Notepad++ all offer folder view in their interfaces.
All the effort put into quality subdomain enumeration has led to this moment. Now, I have a nearly full map of a client’s external landscape.
In the words of Emmanuel Goldstein:

Searching GitHub
GitHub offers many opportunities for developers to leave secrets or sensitive information within the code, commits, and comments of a public repo. Therefore, I like to use automated tools to search for subdomains, email addresses, internal code, and sensitive information regarding a client. For large organizations, or organizations that have very common keywords in their name, be prepared to look through GitHub results for a while. I often split my GitHub result analysis over the course of 20–30-minute increments, otherwise I get stuck on GitHub and waste time.

GitGot – M – I use GitGot for semi-automated discovery of GitHub information related to a client. I like this tool as it allows me to tune the search results. For example, I can remove similar repos from being displayed, view the entire contents of a file, and go backward through search results if I realize something was valuable that I disregarded previously.
# gitgot.py -q domain.comTruffleHog – O – If I discover GitHub repositories using GitGot that have some information but are too large to manually review, I use TruffleHog and specify the repository or user for TruffleHog to scan and extract any secrets that may exist.
Repository:
# trufflehog git https://github.com/trufflesecurity/test_keys --only-verifiedUser/Organization:
# trufflehog github --org=trufflesecurity --only-verifiedDiscovering Usernames
Usernames are valuable for credential attacks. While I won’t explain how to use these usernames, I will cover my go-to methods for username enumeration. At a minimum, I will take the list of valid usernames and send them through paid API services like Hunter.io to identify breaches they were involved in. Then, I deliver that information to the client so they are aware of breached usernames.
IntelX – M – If you did subdomain enumeration already, then you may have the downloaded zip file that I explained earlier in this post. This command parses out emails, sorts them, removes duplicates, and uses grep to display only the contents that match your client.
# cat * | grep -a -E -o '\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b' | sort -u | grep <clientname>theHarvester – M – If you did subdomain enumeration already, then you likely have the JSON data from theHarvester mentioned earlier, you can parse out usernames using the below command.
# cat theHarvester.json | jq -r '.emails | .[]' | sort -ulinkedin2username – M – This is a web scraper that uses LinkedIn credentials to extract names of employees from a company.
-c This is the exact name of the company in the LinkedIn URL bar, see additional description here.
-n This is the email url of the company.
# linkedin2username.py -c <company> -n domain.com -o output_folderDiscovering Passwords
I do not place substantial effort into discovering passwords. It is very rare for breached credentials to be valid at the time of testing. If you have access to recent breach data, then this may be a viable option for gaining access. What I look for in breached data is passwords that abide by the password policy implemented in my client’s environment at the time of testing. You can find leaked credentials in IntelX or other breached data repositories.
Cloud Buckets & Files
Cloud Buckets that are publicly exposed may contain files that are not meant to be publicly accessible. If you can find cloud buckets that have global read/write to them, then you could attempt to upload data to the bucket which could be detrimental for a client. I use GrayhatWarfare which has various free and paid access levels to interact with the data. I also use cloud_enum to query buckets and files from cloud providers.
cloud_enum – M – cloud_enum queries for buckets and files from Amazon, Entra, and Google Cloud Platform.
-k Specify keywords and multiple of them in the command line or you can use -kf with a keyword file.
-l Write the output to a file.
# cloud_enum.py -k <keyword> -l cloud_enum_output.logConclusion
I have discussed my methodology for discovering as much actionable information as possible while performing external penetration tests for clients. The major takeaway, that I hope I have expressed clearly, is that you should develop a methodology that enables discovery of information that would otherwise be difficult to find. By emphasizing efforts to align with thorough enumeration techniques, we as penetration testers can provide actionable intelligence to our clients who can then categorize risk to our findings and remediate as necessary.
Now you are ready to enumerate like Crash Override, a.k.a Zero Cool, a.k.a Dade Murphy.
